Envoyer un mail à l’auteur
xavier at ultra-fluide.com
[Remarque : cette page nécessite un navigateur pourvu d'un moteur de rendu MathML pour visualiser les formules mathématiques.]
Afin d'évaluer nos algorithmes, nous avons conduit des tests exploitant un ensemble complet de pages crawlées et indexées par AltaVista en août 2003.
Nous avons décidé de travailler au niveau des sites web plutôt qu'au
niveau des pages pour réduire le besoin en puissance machine. Toutes les
méthodes présentées fonctionnent de façon équivalente qu'il s'agisse de pages
ou de sites web. Nous avons regroupé quelques milliards de pages en 31 003 946
sites, utilisant un algorithme propriétaire inclut dans le moteur
d'AltaVista. Bien que l'algorithme dépende de plusieures heuristiques pour les
réglages, on peut dire grossièrement que toutes les pages individuelles qui
partagent le même nom d'hôte appartiennent au même site web. Une fois les
sites web déterminés, nous considérons l'existence d'un lien du site A vers
le site B si dans le graphe d'origine une ou plusieurs pages du site A
pointent vers des pages du site B.
Nous avons remarqué dès le début que plus d'1/3 des sites (13 197 046) sont
sans référence. Ces sites ne peuvent donc pas être qualifié d'un niveau de
confiance, puisque cette information dépend des liens entrants. Heureusement
ces sites sont en queue de classement dans les résultats de recherche (puisqu'ils
ne reçoivent que la composante statique minimale du PageRank), si bien
que la séparation entre bons et mauvais sites dans ce sous ensemble ne représente pas un véritable enjeu.
Pour nos évaluations, le premier auteur de ce papier a joué le rôle d'oracle,
examinant des pages de différents sites et déterminant si elles utilisaient
des techniques de spamdexing, et produire le classement tel que nous
l'avons vu. Bien sur, l'utilisation d'un auteur en tant qu'évaluateur
augmente les chances d'introduire un biais dans l'étude. Cependant nous
n'avions pas d'autre choix. Ces évaluations manuelles ont pris des semaines :
vérifier un site implique de regarder une grande partie de ses pages, mais
aussi les sites auxquels il est relié pour déterminer s'il y a une intention
de tromper les moteurs de recherche. Trouver un expert bien informé,
travaillant par exemple pour l'un de ces moteurs de recherche renommés tout en ayant
suffisamment de temps à consacrer à ce travail est proche de la mission
impossible. Au lieu de cela, notre auteur a passé du temps à observer par
dessus l'épaule des spécialistes pour apprendre comment identifier le
spamdexing. Il a fait ensuite tous ses efforts pour ne pas introduire de
biais, et appliquer à la lettre les techniques des experts.
Dans un premier temps nous avons fait des tests pour comparer les critères du PageRank inverse et du PageRank élevé tels que décrits respectivement dans les chapitres 5.1 et 5.2. Pour accélérer cette comparaison nous avons exécuté nos tests sur des graphes web réduits qui comprennent l'essentiel de ce qu'il faut pour traiter des questions de spamdexing sur le web. Ces tests sont décrits dans [4]. Pour éviter de trop nous étendre, nous dirons simplement ici que la méthode du PageRank inversé apparaît comme légèrement supérieure pour désigner des échantillons utiles. Ainsi pour la suite des tests sur le web grandeur nature nous avons poursuivi avec le PageRank inversé.
Pour implémenter la sélection de notre échantillon de départ à partir du PageRank inversé nous avons effectué des réglages de détail pour rationaliser les évaluations de l'oracle. D'abord nous avons appliqué le PageRank inversé sur la totalité du graphe des sites web avec : = 0,85 et = 20. Le facteur d'amortissement de 0,85 a été rapporté pour la première fois dans [12], et a toujours été considéré depuis comme le standard pour le calcul du PageRank. Par ailleurs nos tests ont montré que 20 itérations étaient suffisantes pour obtenir la convergence du classement relatif des sites.
Après avoir classé les sites sur le critère du PageRank inversé (étape (2) dans la Figure 5), nous avons concentré notre attention sur les 25 000 premiers sites. Au lieu de passer directement à leur évaluation, nous avons fait un rapide tour d'horizon pour en éliminer quelques uns présentant des problèmes. En particulier nous avons remarqué que les sites à haut niveau de PageRank inversé présentaient un biais vis à vis du spamdexing dû à la présence de clones de l'annuaire DMOZ : des spammers dupliquent le contenu intégral de l'annuaire DMOZ soit dans l'espoir d'augmenter leur "score de centre d'activité" [10] soit dans l'intention de créer des pots de miel comme expliqué dans le chapitre 3.1. Pour nous débarrasser rapidement de ce spamdexing, nous avons retiré de nos 25 000 sites tous ceux qui n'étaient pas répertoriés dans les principaux annuaires, réduisant ainsi l'ensemble initial à approximativement 7 900 sites. En étudiant par sondage les sites filtrés, nous avons déterminé que seule une fraction insignifiante de sites de valeur a été retirée à tord par le processus.
Dès 7 900 sites restants, nous avons évalué les 1 250 premiers (échantillon S), et 178 sites ont été désignés comme des bonnes pages de l'échantillon. Ce travail correspond à l'étape (3) de la Figure 5. La petite taille de l'ensemble des bonne pages est due aux critères extrêmement rigoureux adoptés pour cette sélection : non seulement nous nous sommes appliqués à mettre le spamdexing à l'écart, mais nous avons également appliqué un second filtre visant à sélectionner les sites dont le contrôle est assumé par une autorité clairement identifiable (gouvernement, institution, entreprise). Ce filtre supplémentaire a été ajouté pour assurer la pérennité de l'échantillon de bonnes pages, considérant que la présence de ces autorités réduirait les chances de voir les sites retenus se dégrader rapidement.
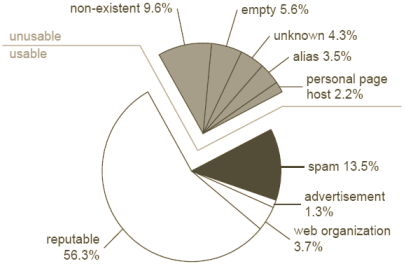
Figure 8: composition de l'échantillon d'évaluation
Afin d'évaluer les métriques présentées au chapitre 3.2, nous avons besoin d'un ensemble X de sites dont nous connaissons l'évaluation via la fonction oracle (c'est un ensemble différent de l'échantillon de départ, qui ne sert qu'a évaluer les performances de nos algorithmes). Nous avons établi un ensemble de 1 000 sites, nombre qui offre suffisamment d'information, et qui reste gérable pour son évaluation par l'oracle.
Nous avons décidé de ne pas sélectionner ces 1 000 sites au hasard, considérant qu'un très grand nombre de sites sont petits (peu de pages) et/ou de faible PageRank (la taille et le PageRank suivent tous les 2 une loi exponentielle rassemblant un très grand nombre de sites dans la queue de la distribution). Comme exposé au chapitre 5.2, il nous parait plus important de détecter le spamdexing parmi les sites de PageRank élevé puisqu'ils ont plus tendance à polluer les premières pages des résultats de recherche. De plus il est difficile pour l'oracle d'évaluer les petits sites pour lesquels la matière à analyser est réduite, il n'y a donc pas d'intérêt non plus à retenir plein de petits sites dans notre ensemble.
Pour assurer la diversité nous avons adopté la méthodologie suivante. Nous avons établi la liste des sites par ordre décroissant de PageRank dans un histogramme de 20 classes. Chaque classe contient un nombre différent de sites, dont la somme des PageRank représente 5% du total des PageRanks. La première classe contient 86 sites de plus fort PageRank, la deuxième 665 sites alors que la dernière en contient 5 millions.
Nous avons construit notre ensemble en retenant au hasard 50 sites de chaque classe. L'oracle évalue les 1 000 sites pour déterminer ceux relevant du spamdexing. Le résultat est présenté Figure 8, un camembert qui montre la façon dont l'ensemble se décompose par type de sites. Nous avons déterminé que 748 sites seront disponibles pour évaluer le TrustRank :
Ces 748 sites forme notre échantillon d'évaluation X. Les 252 restants sont considérés comme inutilisables pour l'évaluation du TrustRank pour plusieurs raisons :
Dans le chapitre 4 nous avons décrit plusieurs stratégies de propagation de la confiance à partir de l'échantillon de départ de bonnes pages. Ici nous allons nous concentrer sur trois valeurs, le TrustRank d'un coté et deux stratégies de référence, et évaluer leurs performances en utilisant notre ensemble X :
1. TrustRank. Nous utilisons l'algorithme Figure 5 ( = 20 itérations et un facteur d'amortissement = 0,85) en utilisant notre échantillon de départ comprenant les 178 bons sites.
2. PageRank. Le PageRank était considéré historiquement comme fortement résiliant devant les assauts du spamdexing puisqu'il s'intéresse à l'importance globale (des changements locaux et limités ont de faibles impacts sur les résultats du PageRank). Il est donc naturel de se demander dans quelle mesure le PageRank peut s'accommoder du spamdexing de notre monde d'aujourd'hui. Nous calculons simplement le PageRank d'un site A comme la valeur de T(A) avec les mêmes paramètres que précédemment M = 20 itérations et l'amortissement α = 0,85.
3. Confiance ignorante. Nous avons généré les scores de la fonction de confiance ignorante pour constituer un autre point de référence. Tous les sites ont reçu un score de 1/2 sauf les 1250 de l'échantillon de départ qui ont reçu les scores de 0 ou 1.
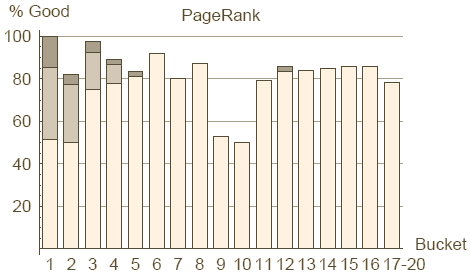
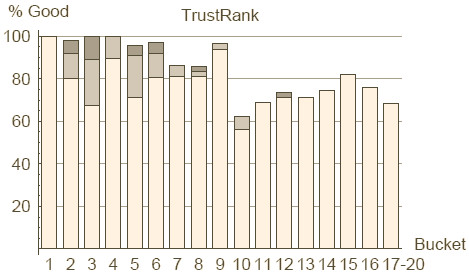
Figure 9 : répartition des bons sites sur les classes du PageRank et du TrustRank
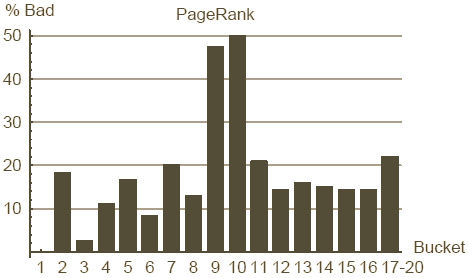
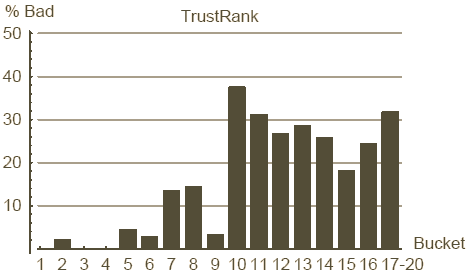
Figure 10 : répartition des mauvais sites sur les classes du PageRank et du TrustRank
Commençons par la comparaison entre PageRank et TrustRank. Rappelons que le PageRank n'incorpore aucune information relative à la qualité d'un site, ni ne pénalise explicitement les mauvais sites. En fait nous verrons qu'il n'est pas rare qu'un site créé par un spammer pointu reçoive un PageRank élevé. A l'inverse notre TrustRank est conçu pour différentier les bons des mauvais sites : nous espérons que les sites relevant du spamdexing ne recevrons pas un haut niveau de TrustRank. Les Figures 9 et 10 comparent cote à cote le PageRank et le TrustRank en respectant le ratio de bons et mauvais sites dans chaque classe. Les classes du PageRank ont été introduites au chapitre 6.3. Nous définissons les classes du TrustRank comme contenant le même nombre de sites que celles du PageRank. Nous avons fusionné les classes 17 à 20 à la fois pour le TrustRank et le PageRank (en effet les 4 dernières classes contiennent plus de 13 millions de sites sans référence. Tous ces sites reçoivent la composante statique du PageRank uniquement et un TrustRank à 0, rendant leur classement impossible).
Les axes horizontaux des Figures 9 et 10 présentent les classes du PageRank et du TrustRank. L'axe vertical de la Figure 9 correspond au pourcentage de bons sites dans une classe, à savoir le nombre de bons sites de l'échantillon de test divisé par le nombre total de sites de l'échantillon de test dans cette classe. Les sites de bonne réputation, de publicité et d'organisation web sont tous considérés comme bons, la contribution relative de ces segments est montrée respectivement en blanc, gris et gris foncé. L'axe vertical de la Figure 10 indique le pourcentage de mauvais sites dans une classe. Par exemple nous apprenons de ce graphique que 31% des sites retenus dans notre échantillon de test et utilisables dans la classe 11 du TrustRank sont des mauvais sites.
Ces graphiques montrent que le TrustRank est un outil honnête de détection du spamdexing. A noter en particulier qu'il n'y a quasiment plus de spamdexing dans les 5 classes du haut pendant qu'il y a un net accroissement de la concentration de mauvais sites sur les classes basses. En même temps il est étonnant de constater que presque 20% de la deuxième classe du PageRank sont des mauvais sites. Le taux de mauvais sites est à son maximum sur les classes 9 et 10 (50% de spam) indiquant probablement que c'est à ce niveau que le spammer moyen parvient à placer son site.
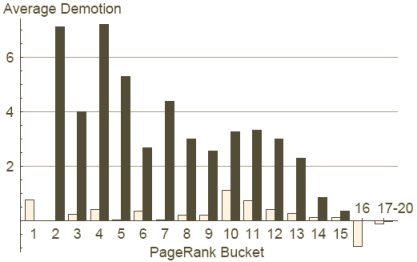
Figure 11 : déclassement par le TrustRank
La Figure 11 offre une autre vue sur la relation entre PageRank et TrustRank. Ce graphique introduit la notion de déclassement correspondant au fait qu'un site présent dans une certaine classe du PageRank se retrouve dans une classe inférieure du TrustRank. Un déclassement négatif est une promotion, c'est à dire le fait qu'un site d'une certaine classe pour le PageRank monte dans une classe supérieure avec le TrustRank. Le déclassement moyen des mauvais sites est un critère important pour évaluer le succès du TrustRank (ou ses manquements) à réduire l'importance des mauvais sites.
L'axe horizontal du graphique 11 décline les classes pour le PageRank.
L'axe vertical indique le nombre de classes dont les sites d'une classe
données de PageRank sont déclassés. Les barres claires représentent les sites
honnêtes, alors que les barres foncées concernent le spamdexing (les sites
publicitaires et d'organisations web ne sont pas représentés).
Ce graphique montre que le spamdexing de la classe 2 a été déclassé en
moyenne de 7 classes, pour se retrouver au niveau de la classe 9. Au
contraire on découvre une promotion des bons sites de la classes 16 qui
montent d'une classe avec le TrustRank par rapport au PageRank.
Ce graphique montre clairement à nouveau que le TrustRank supprime la majeure partie du spamdexing présent parmi les sites les mieux classés. De plus nous constatons que les bons sites restent dans une large proportion à leur position. En conséquence, nous affirmons que, contrairement au PageRank, le TrustRank garantit que les sites du haut du panier sont de bons sites. Nous pouvons dire également que le TrustRank n'est pas vraiment capable de distinguer les bons des mauvais sites dans le bas du classement du fait du peu de liens permettant la discrimination.
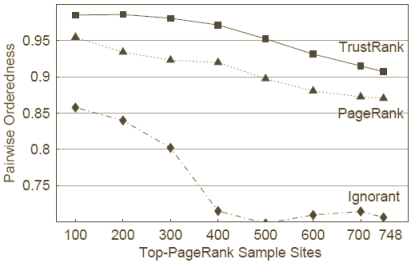
Figure 12 : métrique des paires ordonnées
Nous utilisons la métrique des paires ordonnées présentée au chapitre 3.2 pour évaluer le respect par le TrustRank de la fonction de confiance ordonnée. Pour ce test nous prenons l'ensemble P de toutes les paires de sites pour plusieurs sous-ensembles de notre échantillon test X. Nous commençons en utilisant le sous-ensemble de X des 100 sites de plus haut PageRank, pour faire la vérification sur les sites les plus importants. Ensuite nous ajoutons progressivement de plus en plus de sites à notre sous-ensemble en suivant l'ordre donné par le PageRank. Nous terminons par toutes les paires des 748 sites pour l'évaluation du score de la métrique des paires ordonnées.
Le graphique 12 expose les résultats de ce test. L'axe horizontal traduit
le nombre de sites de l'échantillon de test pour l'évaluation de la métrique,
alors que l'axe vertical donne la valeur de la métrique pour un échantillon
de test donné. Par exemple, les 500 sites de plus fort PageRank donnent
une métrique des paires ordonnées de 0,95.
Le graphique 12 donne également le résultat de la métrique pour la fonction
de confiance ignorante et pour le PageRank. Le recouvrement entre
l'échantillon de départ S et l'échantillon de test X est de 5 bons sites.
Donc tous les sites sauf 5 reçoivent un score de 1/2 de la fonction de
confiance ignorante. Il en résulte que la métrique des paires ordonnées pour
la fonction de confiance ignorante traduit le cas où nous n'avons presque
aucune information sur la qualité des sites. De même la métrique appliquée au
PageRank illustre combien la connaissance de l'importance d'un site aide à
distinguer le bon du mauvais. Nous voyons que le TrustRank surpasse
toujours la fonction de confiance ignorante et le PageRank.
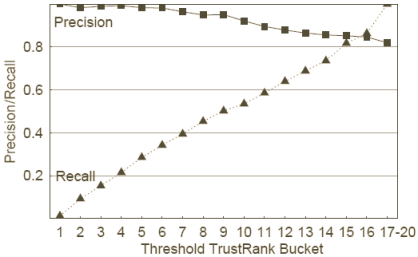
Figure 13 : Précision et rappel
Nos derniers résultats expérimentaux, Figure 13, concernent la performance
du TrustRank au regard des métriques de précision et de rappel. Nous utilisons
comme seuils δ les valeurs limites du TrustRank séparant les 17 classes
du TrustRank présentées au chapitre 6.4.1. Chaque graduation de l'axe
horizontale indique la classe la plus faible pour chaque valeur de seuil.
L'axe verticale donne les métriques de précision et rappel. Par exemple si le
seuil δ est défini comme la valeur permettant aux sites des classes 1 à
10 du TrustRank de constituer l'échantillon à l'exclusion des autres classes,
alors la précision est de 0,86 et le rappel de 0,55.
Le TrustRank affecte les plus hauts scores aux bons sites et la proportion de
mauvais sites augmente graduellement lorsque l'on glisse vers les niveaux bas
de TrustRank. Les métriques de précision et rappel présentent chacune une
variation quasi linéaire avec les classes du TrustRank. Il faut également
noter la précision élevée (0,82) obtenue pour l'échantillon de départ complet
: une telle valeur se rencontre rarement sur les problématiques classiques
d'extraction d'information, ou il est plutôt habituel d'obtenir un large
ensemble de documents dont quelques uns seulement s'avèrent correspondre à la
demande. Par contraste notre ensemble est constitué principalement de bons
documents, tous étant "pertinents". C'est pourquoi le score de la métrique
précision pour la totalité de l'ensemble X est 613/(613+135)=0,82.
Agence de communication Ultra-Fluide : 01 47 70 23 32 - contact at ultra-fluide.com - 44 rue Richer 75009 Paris.




